解析事例
株式会社アイスタット(統計分析研究所)は、統計学 を礎とした情報サービス業 に従事しています。
これまでにのあったご相談の一例を紹介いたします。
扱ったデータや使用した解析手法などについて詳しくご覧いただけます。

予測の事例
▼月次売上予測モデル式作成、予測値算出(クリックすると詳細をご参照いただけます)
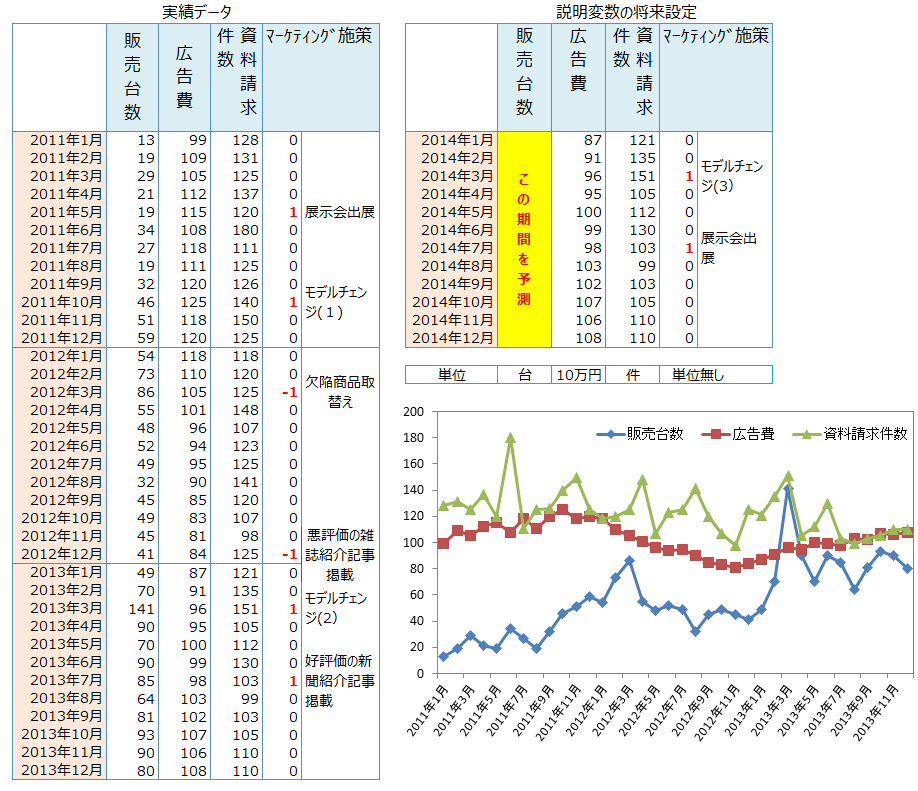
医療機器メーカーの担当者から、「製品告知のための広告費、お客様からの資料請求件数、マーケティング施策有無から自社の医療機器販売台数を予測したい」という相談を受けました。広告費や資料請求件数、マーケティング施策はすべて量的データです。このように量的データで予測モデル式が作成できるのか、作成できるとすれば以下の条件に示す将来設定で 1 年先の予測値を教えてほしいという相談でした。
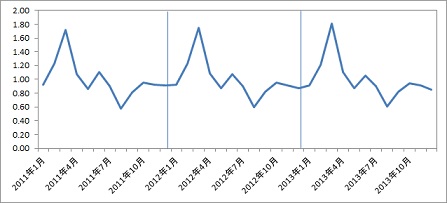
適用データとグラフ
適用する解析手法
分析
相関分析により売上規定要因の検討
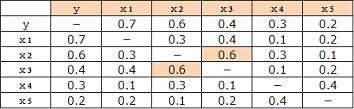
広告費、資料請求件数、マーケティング施策が医療機器販売台数を予測するのに重要な要因であるかを時系列相関係数で調べました。
時系列相関係数は基準としている 0.2 を上回ったので、広告費、資料請求件数、マーケティング施策が医療機器販売台数を予測するのに重要な要因と判断しました。(右表参照)

説明変数の個数は、時系列相関が 0.2 以上であればいくつ用いてもかいません。ただし、説明変数相互の時系列相関が高い(0.5 以上)場合、これらの項目から 1 つだけを用いるというルールがあります。選ぶのは目的変数との時系列相関が最も高いものとします。
このルールを守らず予測モデル式を作成した場合、正しくないモデル式が導かれます。
右表は目的変数と説明変数の総数 6 変数相互の時系列相関を示したものです。 x2 と x3 との時系列相関は 0.6 で 0.5 より大きいので、両方適用できません。 目的変数との時系列相関をみると、x3 より x2 の方が高いので x2 を用います。 したがって、説明変数は x1、x2、x4、x5 の 4 つです。
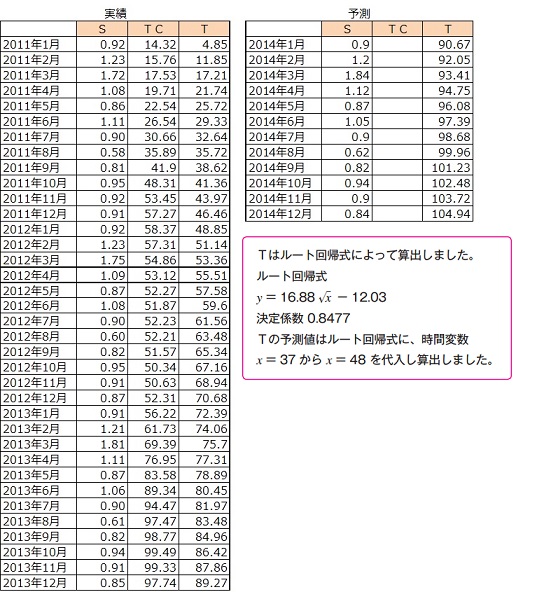
医療機器販売台数の季節変動指数Sの作成
EPA法※によって季節変動指数Sを算出しました。また、Sの予測値はEPA法によって算出された予測値を適用しました。季節変動指数Sは下表で示します。
※クリックすると解説ページに移動します。
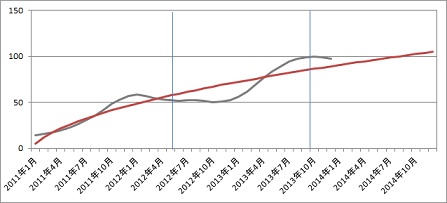
医療機器販売台数のトレンドTの作成
EPA法※によって医療機器販売台数のTCを算出し、TCに回帰分析を行い、トレンドTを求めました。トレンドTは下表で示します。
※クリックすると解説ページに移動します。
◆季節変動指数S
◆トレンドT
予測モデル式
医療機器販売台数を目的変数、トレンドT,季節変動指数S、広告費、資料請求件数、マーケティング施策を説明変数として重回帰分析を行い、予測モデル式を作成します。

実績期間を予測(理論値)
予測モデル式に説明変数のデータを代入し実績期間の予測値(理論値)を算出します。
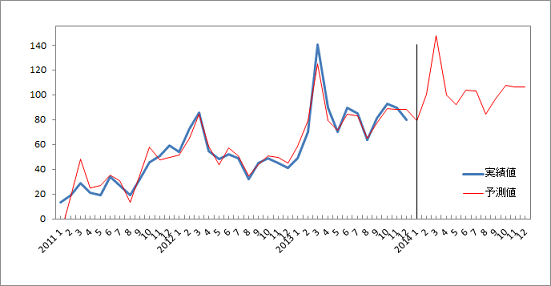
医療機器販売台数の実績値と理論値の比較グラフを作成しました。
予測モデル式の精度
実績値と理論値はほぼ一致し、予測モデル式は予測に使えそうです。実績値と理論値の一致度を決定係数で調べました。決定係数は 0.9166 で基準の 0.5 を上回っているので予測モデル式は予測に適用できると判断しました。
| 決定係数 | 0.9166 |
予測
説明変数の将来値を予測モデル式に代入し 12ヶ月先までを予測しました。
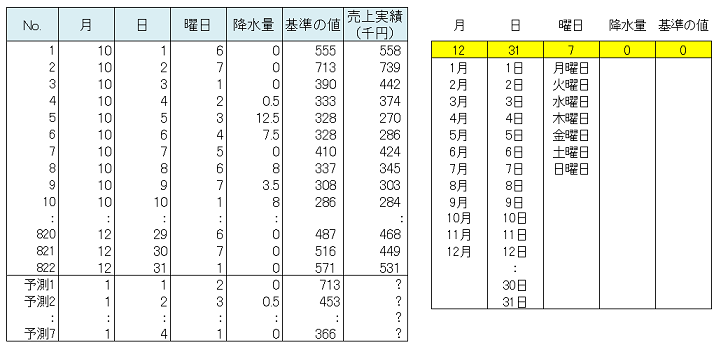
2014 年 3 月を例として予測値算出の手順を右表に示します。
◆2014年3月の予測値算出手順

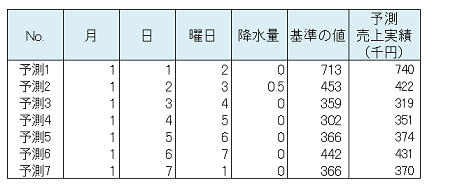
2014 年3 月の予測値は148 台です。2014 年1 月以降の予測値を以下に示します。
◆予測値

分析結果
医療機器販売台数は2012 年に欠陥品が発生し雑誌記事で悪評価されるなどで低迷した。
2013 年のモデルチェンジが好評を得たことにより上昇基調に転じた。
2014 年は、3 月のモデルチェンジ、7 月の展示会出展が成功することを想定すると、2013年同様の上昇基調が続くであろう。
▼日次売上予測モデル式作成、予測値算出(クリックすると詳細をご参照いただけます)
人気ベーカリーショップの担当者に、「日次の売上を予測したい」という相談を受けました。
人気ベーカリーショップの担当者は、経験をたよりに月、日、曜日、降水量などを加味して予測をしていましたが、統計的な手法で精度の高い予測値を算出できないかとの相談でした。
適用データ
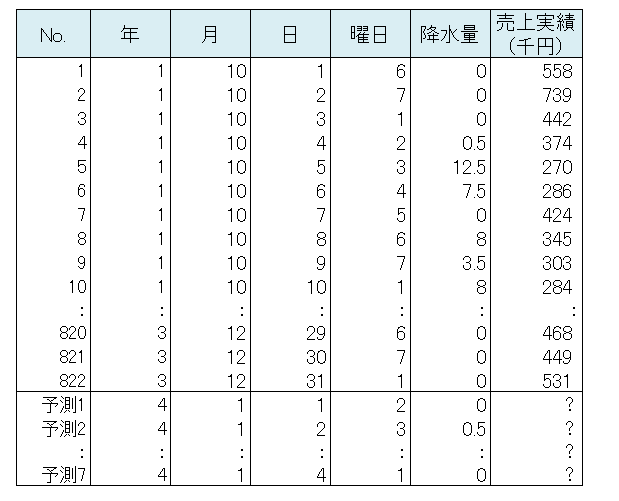
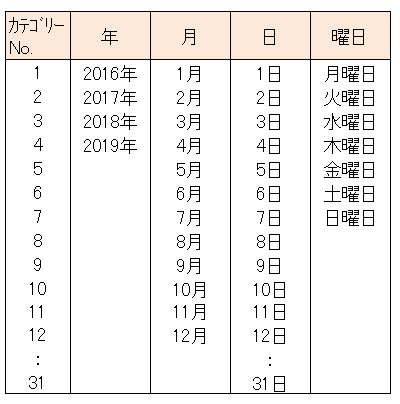
適用する解析手法
分析
売上実績との相関
売上実績との年、月、日、曜日、降水量との関係を調べます。
目的変数である売上実績は数量データ、説明変数である年、月、日、曜日はカテゴリーデータ、降水量は数量データです。
数量データとカテゴリーデータはカテゴリー別平均と相関比、数量データと数量データは相関図と単相関係数で関連があるかどうかを把握できます。
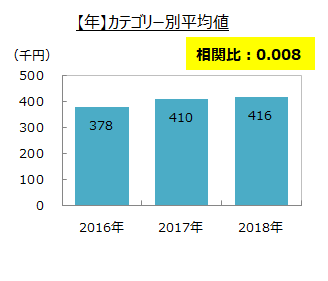
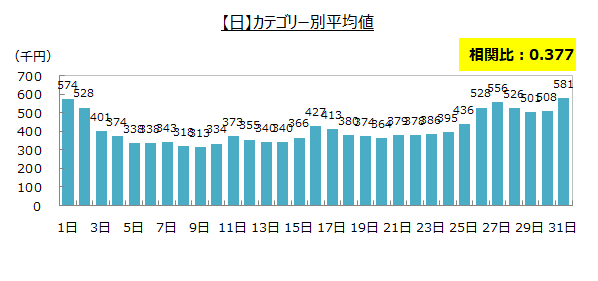
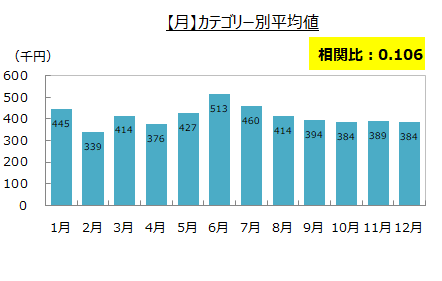
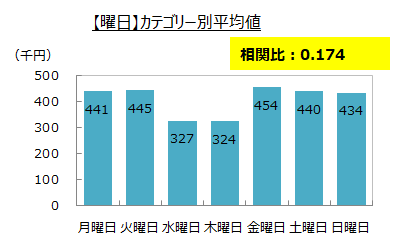
カテゴリー別平均と相関比
売上実績との相関比を見ると、月、日、曜日は基準の0.1を上回りましたが、年は0.008 と0.1を下回りました。
基準を上回った月、日、曜日の3つの項目は予測するのに重要な要因と判断しました。
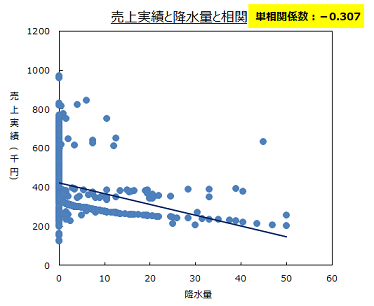
相関図と単相関係数
売上実績と降水量との単相関係数の絶対値は、基準の0.3を上回りましたので、降水量は予測するのに重要な要因と判断しました。
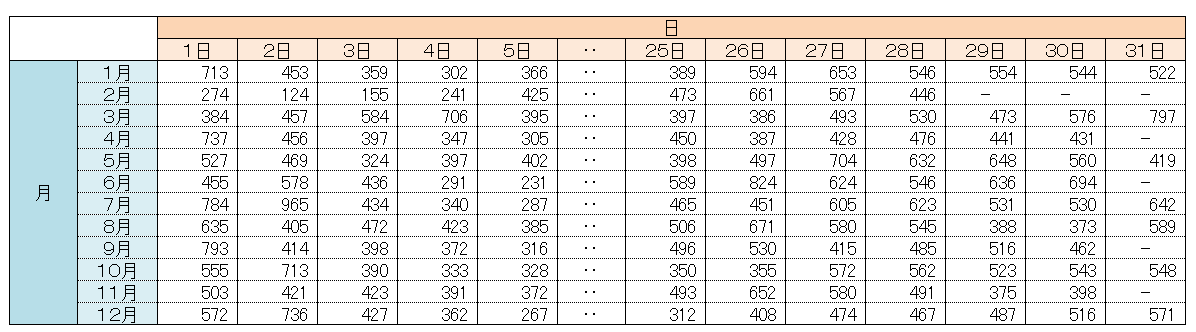
説明変数に基準の値を追加
説明変数に月、日別に売上実績を平均した「基準の値」を追加しました。
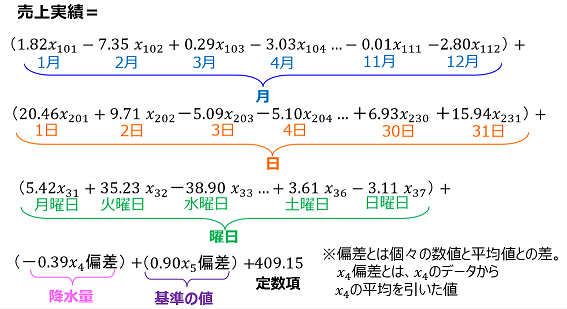
予測モデル式
売上実績を目的変数、月、日、曜日、降水量、基準の値を説明変数として、拡張型数量化1類を行い、予測モデル式を作成しました。
※拡張型数量化1類は、説明変数が数量データとカテゴリーデータが混在しているときに予測モデル式を作成する方法です。
予測モデル式の精度
実績値と予測値の一致度を決定係数で調べました。決定係数は 0.918 で基準の 0.5 を上回っているので予測モデル式は予測に適用できると判断しました。
予測
説明変数の将来値を予測モデル式に代入し 7日先までを予測しました。
分析結果
拡張型数量化1 類は「カテゴリースコア」という値を算出します。
カテゴリースコアは、売上実績について平均値を算出し、求められた平均値から売上実績全体平均(この例は409.15(千円))を引いた値です
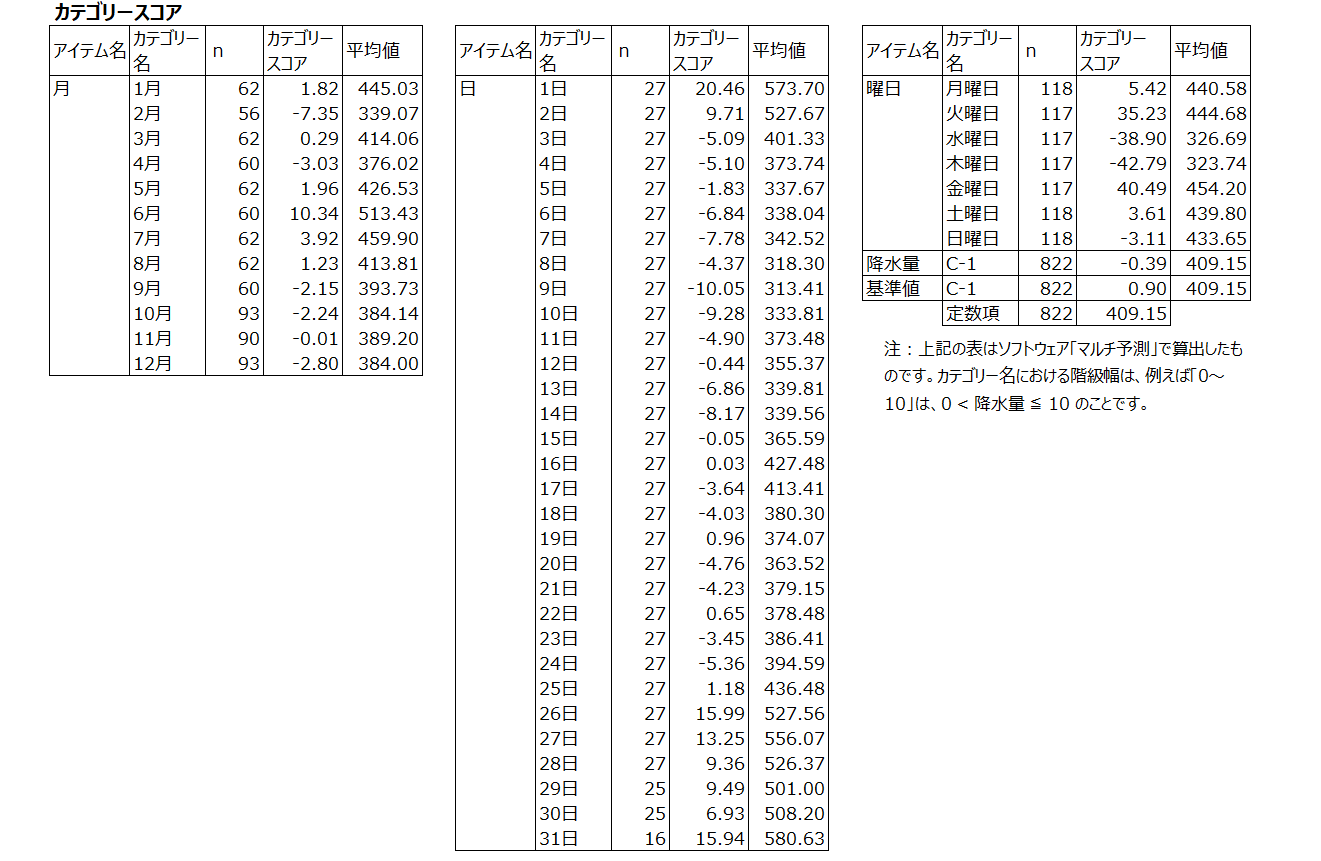
カテゴリースコアから、月の売上貢献度は、”6月”が一番高く10.34(千円)です。
日の売上貢献度は、”1日”が一番高く20.46(千円)です。
曜日の売上貢献度は、”金曜日”が一番高く40.49(千円)です。
降水量が多いほど売上実績は少なくなる傾向が明確となりました。
▼営業活動と売上額の相関分析、営業活動成果検証(クリックすると詳細をご参照いただけます)
製薬会社の市場調査部担当者から相談を受けたテーマです。我が社の主力製品A薬剤の売上は、ここ数年減少傾向にあります。減少の理由はいろいろ考えられますが、競合薬剤の市場シェアが増加していること、A薬剤の営業回数が少ないこと、医師へのA薬剤製品説明会の効果があまりないことなどが考えられます。
このことを統計学的に説明できる方法がないか、またこれらの要因は売上を予測するのに重要な要因となり得るかを教えてほしいという相談です。
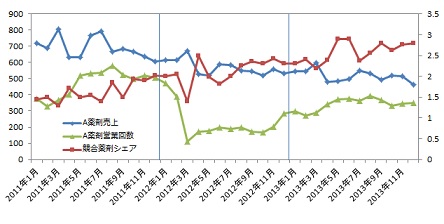
適用データとグラフ
適用する解析手法
分析
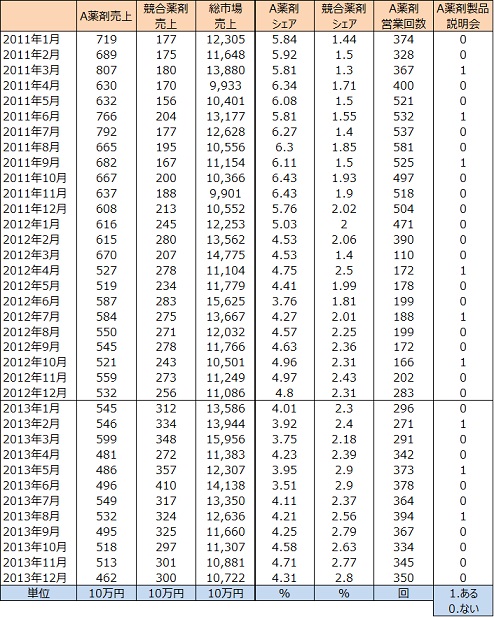
A 薬剤の売上は減少傾向、競合薬剤のシェアは増加傾向で推移しています。競合薬剤の増加に伴い、A 薬剤の売上が減少していると考えられます。両者の関係を時系列相関で見ると、- 0.5849 となりました。時系列相関の絶対値0.5849 は基準としている0.2 を上回ったので、競合薬剤のシェア増加はA 薬剤の売上減少に影響を及ぼしているといえます。
A 薬剤の営業回数は2012 年3 月に大きく減少しましたが、それ以降少しずつ増やしているものの、2013 年末現在において2011 年の水準には達していません。そのような状況でも営業回数が多い月はA 薬剤の売上は増加する傾向が見られます。両者の関係を時系列相関で見ると0.2960 となり、基準としている0.2 を上回ったので、営業回数の増減はA 薬剤の増減に影響を及ぼしているといえます。
A 薬剤の売上とA 薬剤製品説明会との関係を時系列相関で調べました。時系列相関の値は0.1157 で基準の0.2 を下回り、製品説明会をしても売上増につながらないということがわかりました。

注. 時系列相関はトレンドTの影響を除去した時系列データ相互の関係を見る方法です。
一生懸命営業しても、その効果(売上増)はその月に現れるとは限りません。もしかしたら効果は1ヶ月後、あるいは2ヶ月後かもしれません。
売上と営業回数との関係を、月数をずらして見る相関を「タイムラグ相関」といいます。
タイムラグ相関もトレンドTの影響を除去した時系列データ相互の関係を見ることができます。この相関を「タイムラグ時系列相関」といいます。
運用データのついて時系列タイムラグ関数を算出しました。
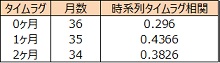
タイムラグ1ヶ月の時系列相関係数は0.4366 と0ヶ月の0.2960 より高く、A 薬剤営業回数の効果は1ヶ月後に現れることがわかりました。
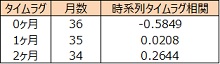
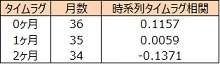
競合薬剤シェア、A 薬剤製品説明会の時系列タイムラグ相関を算出しましたが、0ヶ月の相関が最大でした。
◆競合薬剤シェア
◆A薬剤製品説明会
分析結果
A 薬剤の売上を予測するのに競合薬剤シェア、A 薬剤営業回数は欠かせない要因であることがわかりました。A 薬剤製品説明会は重要でありませんでした。
A 薬剤の売上予測モデル式を作成する際、A 薬剤営業回数はタイムラグ1ヶ月を考慮することを重要事項として記しておきます。
▼施設別売上ポテンシャル算出モデル式作成、施設評価(クリックすると詳細をご参照いただけます)
製薬会社の市場調査部の担当者からの相談です。MR(医薬情報提供者)が医師に面会し、B 薬剤の医薬情報を提供しています。「MR 面会回数」は医師に面会した回数 を、施設ごとに数えた延べ回数です。
インターネットによってA 薬剤の医薬情報提供を、医師に配信するサービスをしている 会社があります。「医師視聴人数」はそのサービスを視聴している医師を、施設ごとに数え た延べ人数です。
製薬会社はB 薬剤を処方採用・増量してもらいたいと考えている施設をターゲット施設、そうでない施設をノンターゲット施設としています。
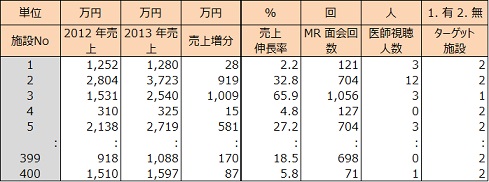
400 の施設(病院・医院・診療所)について、B 薬剤売上及び伸長率、MR 面会回数、医師視聴人数、ターゲット施設有無のデータがあります。
これらのデータを解析し、次の3 つを明らかにしたいという相談です。
① MR 面会回数が多い施設ほど、医師視聴人数が多い施設ほど売上伸長率は高いか。ターゲット施設はノンターゲット施設に比べ売上伸長率は高いか。
② MR 面会回数、医師視聴人数、ターゲット施設有無から、施設ごとの売上伸長率を予測するモデル式を作成したいがどうすれば良いか。
③ MR 活動とインターネットとを組み合わせて営業をした場合、どのような配分で営業をすれば売上伸長率を高くすることができるか。
適用データ
適用する解析手法
分析
B 薬剤の売上と売上伸長率の現状
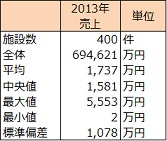
施設別の売上額の基本統計量と分布を調べました。
全施設の2013 年の売上平均値は1,737 万円です。売上額の分布を見ると501~1000 万円以下の施設が最も多く、501~2500 万円以下の施設で7 割を占めます。
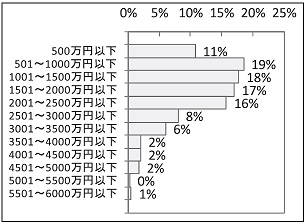
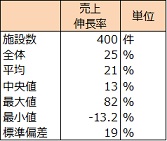
次に、施設別の売上伸長率の基本統計量と分布を調べました。
全施設の2013 年対前年の売上伸長率は24.9%です。売上伸長率の分布を見ると0~10%以下の施設が最多。0%以下(減少)の施設は4%、50%以上伸びた施設はほぼ1 割ありました。
◆2013 年売上の基本統計量と分布
◆2013年対2012年売上伸長率の基本統計量と分布
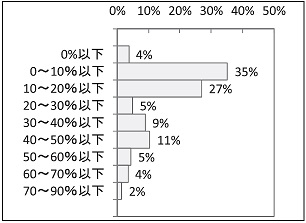
売上規定要因の現状
MR 面会回数の平均値は511 回/1 施設です。200 回以下の施設は27%、701 回以上は24%でした。医師視聴人数の平均値は5.1 人/1 施設です。未視聴(0 人)施設は42%、11 人以上の施設は16%でした。ターゲット施設は25%です。
◆2013 年データの基本統計量と分布
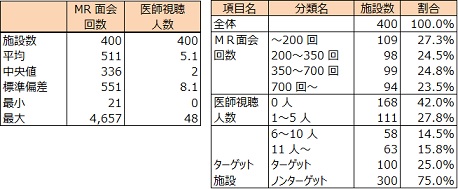
B 薬剤の売上伸長率と売上規定要因との関係
薬剤の売上伸長率と売上規定要因との関係をカテゴリー別平均で調べました。
・MR 面会回数が多い施設ほど売上伸長率は高くなる傾向がみられました。
・医師視聴人数が多い施設ほど売上伸長率は高くなる傾向がみられました。
・ターゲット施設はノンターゲット施設に比べ売上伸長率は高い値を示しました。
・ 売上伸長率との単相関係数を見ると、MR 面会回数、ターゲット施設は0.3 を上回りましたが、医師視聴人数は0.25 と0.3 をやや下回りました。
・ 医師視聴人数は弱い相関係数でしたが、これら3 つの項目は予測するのに重要な要因と判断しました。
◆カテゴリー別平均
◆単相関係数

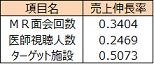
予測モデル式
B 薬剤売上伸長率を目的変数、MR 面会回数、医師視聴人数、ターゲット施設有無を説明変数として拡張型数量化1 類を行いました。拡張型数量化1 類より求められた関係式を施設別のB薬剤の売上伸長率を予測するモデル式としました。以下、予測モデル式の結果を示します。

実績期間を予測(理論値)
400 施設の説明変数のデータを予測モデル式に代入し、400 施設の売上伸長率の予測値(理論値)を算出します。
実績値を縦軸、理論値を横軸に散布図を描いてみると、実績値と理論値はほぼ一致していることがわかり、予測モデル式は予測に使えそうです。
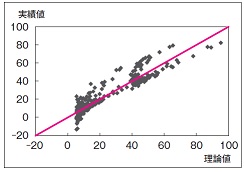
予測モデル式の精度
実績値と理論値の一致度を決定係数で調べました。決定係数は0.8838 で基準の0.5 を上回っているので、予測モデル式は予測に適用できると判断しました。
予測
MR 面会回数が500 回、300 回、0 回の場合、医師視聴人数が8 人、4 人、0 人の場合、ターゲット施設がある場合、ない場合の組み合わせを以下の18 のパターンを設定しました。
18パターンを予測モデル式に代入し予測値を算出しました。
当然ながら、MR 面会回数、医師視聴人数が多いパターンほど売上伸長率は高くなります。だからといって、それぞれを多くすれば経費が嵩みます。そこで経費の上限を決め、その経費内に収まり売上伸長率が最も高いパターンを見出します。
分析結果
①「 MR面会回数が多い施設ほど、医師視聴人数が多い施設ほど売上伸長率は高い」、「ターゲット施設はノンターゲット施設に比べ売上伸長率は高い」といえます。
② MR 面会回数、医師視聴人数、ターゲット施設有無から、施設ごとの売上伸長率を予測するモデル式は、以下の式となります。決定係数は0.8838 で予測に適用できます。

③ 経費の関係でターゲット施設に対しては、MR 面会活動300 回、医師視聴人数8 回としたとします。その設定で見込める売上伸長率は44.8%です。
多変量解析の事例
▼傾向スコアマッチング分析(クリックすると詳細をご参照いただけます)
1. データ
健康診断の検査値の一つにγ-GTP(ガンマジーティーピー)がある。
γ-GTPは肝臓や胆管の細胞がどれくらい壊れたかを示す指標で、検査値が成人男性の場合100(基準は50)を超えると、肝硬変、肝がん、脂肪肝、胆道疾患の可能性があるといわれている。
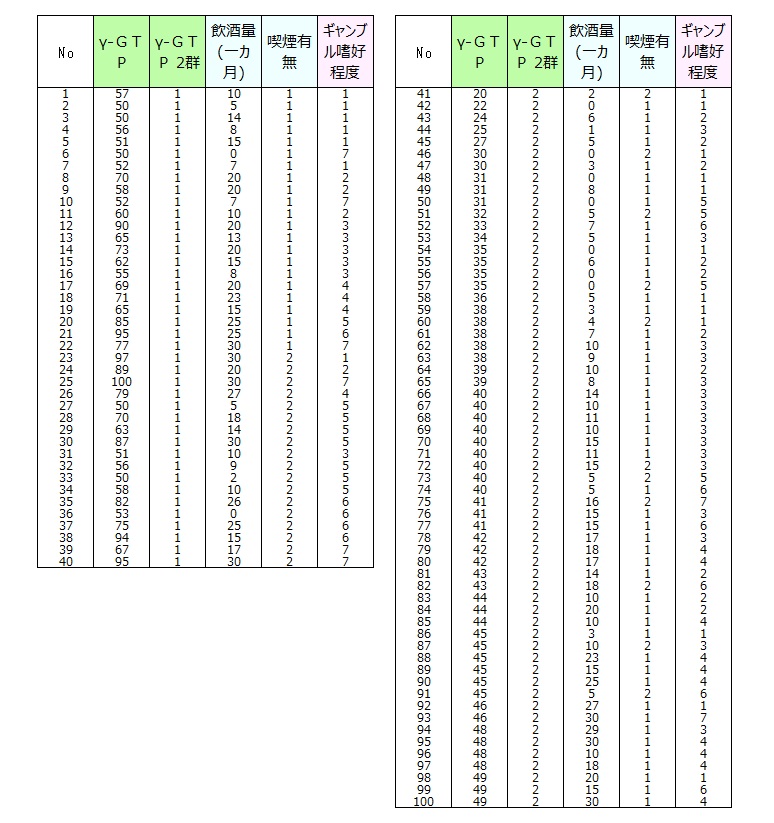
下記は100人の成人男性について、γ-GTP、飲酒量(一カ月に飲酒する日数)、喫煙有無、ギャンブル嗜好(7件法)を調べたものである。
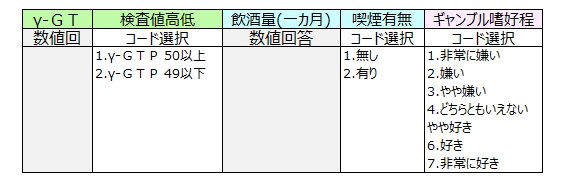
データ
2. 検証内容
① 飲酒量はγ-GTPに関係があるかを検証する。
② 喫煙有無はγ-GTPに関係があるかを検証する。
③ ギャンブル嗜好はγ-GTPに無関係であることを検証する。
3. γ-GTP 2群間の有意差検定
γ-GTPの「50以上」を群1=高群、「49以下」を群2=低群として、γ-GTP(2群)のデータを作成した。
① 飲酒量の平均は、高群16.2(日)、低群11.0(日)で高群が低群を5.2ポイント上回った。p値0.0037<0.05より高群は低群に比べ有意に高いといえる。このことから、飲酒量はγ-GTPに関係があることが検証できた。
② 喫煙有無において「有り」の割合は、高群45.0%、低群18.3%で高群が低群を26.7ポイント上回った。p値0.0037<0.05より高群は低群に比べ有意に高いといえる。このことから、喫煙有無はγ-GTPに関係があることが検証できた。
③ ギャンブル嗜好程度の平均は、高群4.03(点)、低群3.17(点)で高群が低群を0.86ポイント上回った。p値0.0252<0.05より高群は低群に比べ有意に高いといえる。ギャンブル嗜好程度はγ-GTPに無関係と思われていたが関係性があるという結論になった
4. 相関分析
① 飲酒量とγ-GTPとの相関係数は0.6658(p値<0.05)で、飲酒量はγ-GTPへの影響要因といえる。
② 喫煙有無はγ-GTPとの相関係数0.3076(p値<0.05)で、喫煙有無はγ-GTPへの影響要因といえる。
※ 喫煙有無は距離尺度でないが、「喫煙しない」を0点、「喫煙する」を1点として距離尺度に変換して相関係数を算出した。
③ ギャンブル嗜好とγ-GTPとの相関係数は0.3580(p値<0.05)で、ギャンブル嗜好はγ-GTPへの影響要因といえる。
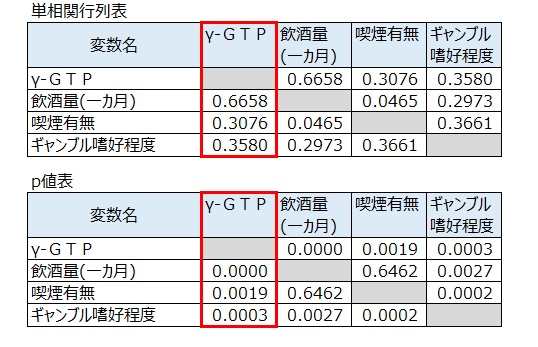
5. 見かけの相関、真の関係
相関関係を図で示す。
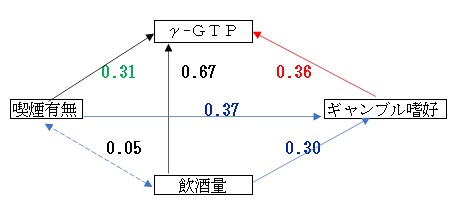
「γ-GTPとギャンブル嗜好」の相関は0.36、「γ-GTPと喫煙有無」は0.31で前者の方が高い。ギャンブル嗜好の方が喫煙有無より、γ-GTPに影響度が高いといえるだろうか?
「喫煙有無とギャンブル嗜好」の相関は0.37、「飲酒量とギャンブル嗜好」の相関は0.30でどちらも相関関係が見られ、喫煙する人ほど、飲酒量が多い人ほどギャンブル嗜好程度が高いといえる。ギャンブル好きだからγ-GTPが高いのではなく、ギャンブル好きは喫煙し、飲酒量が多いからγ-GTPが高いと推察できる。
「γ-GTPとギャンブル嗜好」の相関0.36は見かけの相関である。「γ-GTPとギャンブル嗜好」の真の関係は喫煙有無や飲酒量の影響を除去したものでなければならない。
このような真の関係を把握する方法に、①重回帰分析、②傾向スコアマッチング分析がある。
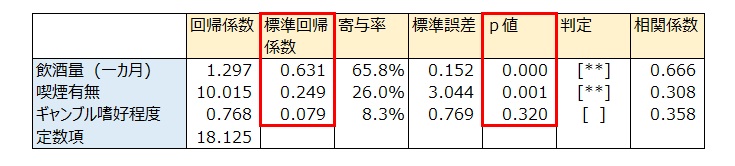
6. 重回帰分析
γ-GTPを目的変数、飲酒量・喫煙有無・ギャンブル嗜好程度を説明変数として重回帰分析を行った。
標準回帰係数を見ると、ギャンブル嗜好程度は0.079と小さく、またp値=0.320>0.05で、ギャンブル嗜好はγ-GTPへの影響要因でないといえる。
重回帰分析は、目的変数と説明変数の真の関係を明らかにする手法である。

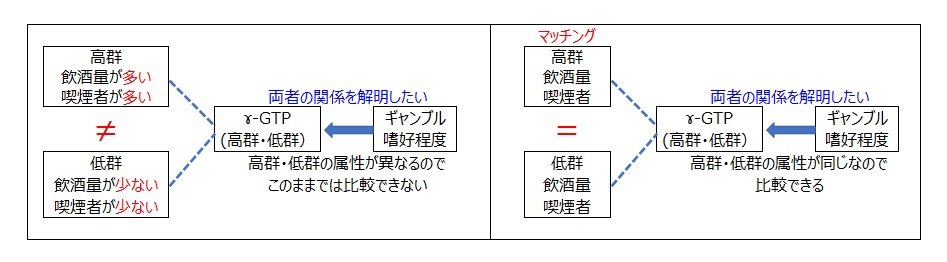
7. 傾向スコアマッチング分析とは
高群は飲酒量多者や喫煙者が多く、低群は飲酒量少者や非喫煙者が多い。このような状況でギャンブル嗜好程度の平均について高群と低群を比較すれば「ギャンブル嗜好と飲酒量や喫煙は相関関係がある」ので、ギャンブル嗜好程度は高群の方が低群より高くなるのは当然である

ギャンブル嗜好程度の平均を高群と低群で比較する際、両群の飲酒量や喫煙有無が同等であれば真の比較ができる。
すなわち、高群と低群で飲酒量や喫煙有無が似ているサンプルだけを取り出して比較すればよい。
具体的には両群から似ている要素をもつデータを見つけてペアにすることである。
※統計学において異なるサンプルで,似ている要素(交絡因子という)をもつデータを見つけてペアにすることをマッチングと言う。
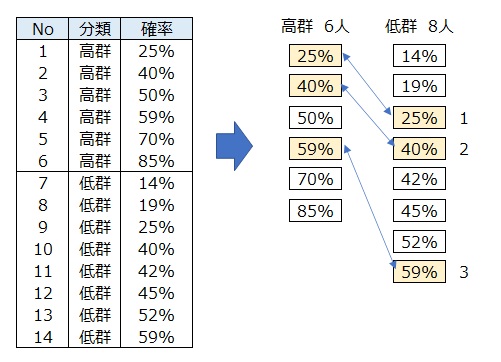
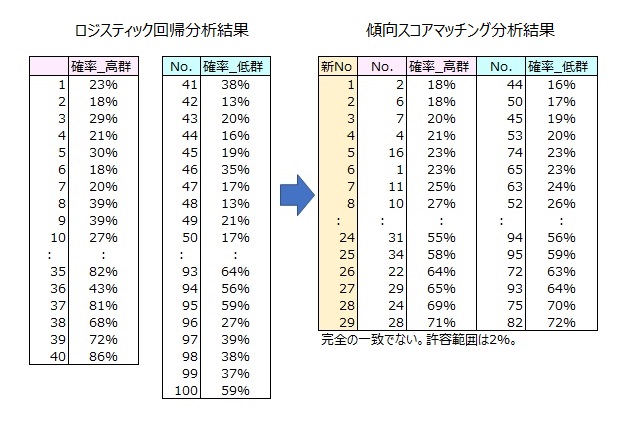
14人について、飲酒量・喫煙有無から各サンプルがγ-GTP高群となる 確率を求めたとする。
両群から確率が似ている(同じ)サンプルを見つけてペアにする。
高群6人、低群8人においてペアは3人である。選ばれた3人は、「飲酒量・喫煙有無」の状況(傾向)が似ている人である。
確率を傾向スコアという。
同じような傾向を持つ人をペアにする方法を傾向スコアマッチングと言う。
傾向スコアは,目的変数を高群=1,低群=0、説明変数を交絡因子である飲酒量、喫煙有無にしてロジスティック回帰を行うことで求められる。
ロジスティック回帰で導かれる各サンプルの判別スコアを傾向スコアとする。
マッチングされたペアデータについて、検証したい原因項目(具体例はギャンブル嗜好程度)と目的変数(γ-GTP)について相関検定や有意差検定を行う。
交絡因子の傾向スコアでマッチングしペアを見つけ、ペアデータについて目的変数と原因変数の関係を検証する方法を傾向スコアマッチング分析という。
8. ロジスティック回帰分析
ロジスティック回帰分析は目的変数が2群のカテゴリーデータ、説明変数が数量データとする多変量解析の手法である。
説明変数の目的変数に対する影響度を示すWald-squareを算出する。
各サンプルについて、2つの群A,BについてAとなる確率である「判別スコア」を算出する
具体例について行うロジスティック回帰分析は2つある。
① 目的変数:γ-GTP 説明変数:交絡因子 & 原因変数
② 目的変数:γ-GTP 説明変数:交絡因子
①-1. 把握内容
γ-GTP高群・低群の判別に影響する要因を解明する
目的変数: γ-GTP高群、低群
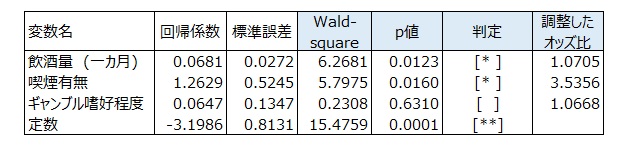
説明変数: 飲酒量、喫煙有無、ギャンブル嗜好適度
使用する結果: Wald-square、p値
オッズ比1以上。p値<0.05の説明変数は
高群・低群の判別に影響する要因といえる。
影響度は見かけでなく真である。
①-2. 結果
γ-GTPへの影響度をWald-squareでみると、1位は飲酒量、2位は喫煙有無である。
ギャンブル嗜好程度のWald-squareは小さく、p値>0.05より、ギャンブル嗜好程度はγ-GTPへの影響要因でないといえる。
②-1. 把握内容
ギャンブル嗜好程度とγ-GTPとの真の関係を明らかにしたい。
マッチングし両群の傾向が同じ(飲酒量、喫煙有無が同じ)サンプルのペアを作りたい。
目的変数: γ-GTP高群、低群
説明変数: 飲酒量、喫煙有無(ギャンブル嗜好程度は入れない)
使用する結果: 判別スコア(確率)
※傾向を調べる項目を交絡因子という。
具体例における交絡因子は飲酒量、喫煙有無である。
②-2. 結果
Wald-square、p値の出力結果は見なくてよい。
判別スコア(確率)が重要である。
※マッチングには最近傍法、フルマッチング(完全に一致)がある。上記は最近傍法によるものである。
9. マッチング後の解析
マッチング後のペアデータでγ-GTP2群間の有意差検定を行う。
γ-GTPの「50以上」を群1=高群、「49以下」を群2=低群とする。
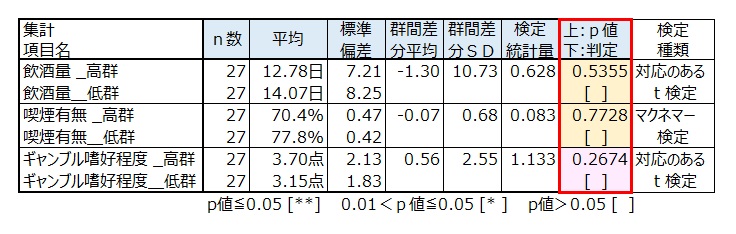
① 飲酒量の平均は、高群14.03(日)、低群13.83(日)で高群が低群を0.2ポイント上回った。p値0.9070>0.05より高群は低群に比べ有意に高いといえない。
このことから、マッチング後の飲酒量は高群・低群で同等である。
② 喫煙有無において「有り」の割合は、高群75.9%、低群79.3%で高群が低群を3.4ポイント下回った。p値0.7055>0.05より高群は低群に比べ有意に高いといえない。
このことから、マッチング後の喫煙有無は高群・低群で同等である。
③ ギャンブル嗜好程度の平均は、高群3.52(点)、低群3.93(点)で高群が低群を0.41ポイント下回った。p値0.3750>0.05より高群は低群に比べ有意に高いといえない。
マッチング前のギャンブル嗜好程度はγ-GTPに関係と思われていたが、このことから、関係性があるといえないことが検証できた。
マッチング後のサンプルサイズが30を下回る場合、母平均の有意差検定は、U検定を適用する。
この例題は30を下回ったのでU検定を行うのが正しいが省略する。
アンケート調査の事例
▼消費者セグメンテーション(クリックすると詳細をご参照いただけます)
消費者セグメンテーションとは
消費者セグメンテーションとは、消費者を分類する方法です。
その背景にあるのは「消費者のニーズの多様化」です。
市場が成熟化し生活者のニーズが多様化している現在、万人向けの商品を開発し販売することは効果的とはいえません。なぜなら全てのニーズを一度に満たそうとすればするほど商品コンセプトは平均的なものになってしまいます。
そこで、求められるのが消費者セグメンテーションです。
戦略的に消費者のセグメンテーションを行い、セグメントにフォーカスしてプランをたて、マーケティング活動をすれば、より効果的にビジネス成果を得ることが可能となります。
消費者セグメンテーションの目的
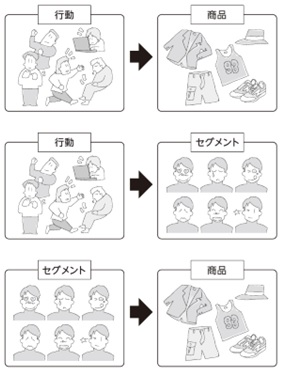
生活行動、購買行動と新製品選択との関係を明らかにしたいことがあります。しかしながら、人々の生活行動、購買行動は多種多様で、両者の因果関係の解明はやっかいなテーマといえます。
そこで数多くある生活行動や購買行動の項目に多変量解析を適用し消費者をセグメントします。
どのようなセグメントに属する人が、どのような 新製品を嗜好するかを明らかにすることを目的とします。
消費者セグメンテーションの手順と解析方法
消費者のセグメント化は多変量解析を適用して行います。統計解析が作成したセグメントに名前を付けねばなりません。この作業は分析者であるあなたが付けます。
ここでは、セグメント化に適用する解析手法とネーミングの仕方について学びます。
消費者セグメンテーションの解析手順
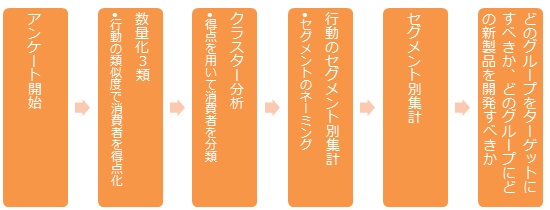
数量化3類とは
数量化3類はアンケート調査の回答者と回答選択肢を得点化する解析手法です。
回答の仕方が似ている消費者には類似した得点、似ていない消費者には異なる得点をつけます。この得点をサンプルスコアといいます。
回答のされ方が似ている選択肢には類似した得点、似ていない選択肢には異なる得点をつけます。この得点をカテゴリースコアといいます。
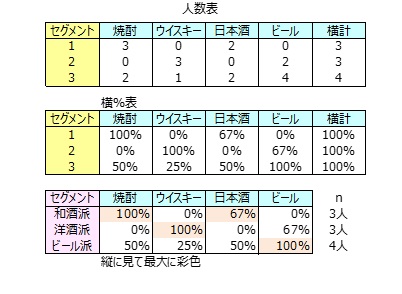
数量化3類のためのアンケートデータ
数量化3類を理解するために、簡単なアンケートの回答選択肢と回答データを示します。
【具体例】

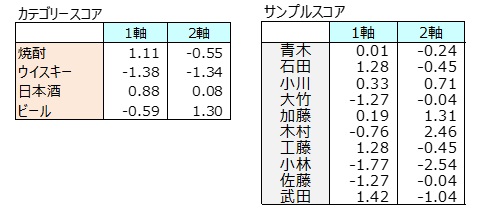
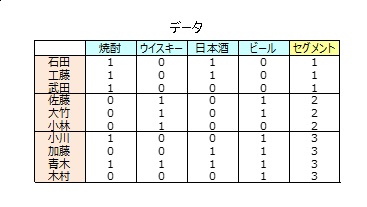
カテゴリースコア、サンプルスコア
数量化3類は、呑まれ方が似ているお酒には類似した得点を、呑み方が似ている人には類似した得点をつけます。 回答選択肢(カテゴリー)や回答者(サンプル)を得点化します。 お酒の得点をカテゴリースコア、回答者の得点をサンプルスコアといいます。 どちらも2個の得点が付けられます。 2個の得点を1軸、2軸といいます。
縦軸に1軸のカテゴリースコア、横軸に2軸のカテゴリースコアをとり点グラフを作成します。
点グラフの点の配置から軸を解釈します。
1軸 「和酒が好きか」「洋酒が好きか」を判別する軸
2軸 アルコール度数が「弱い酒が好きか」「強い酒が好きか」を判別する軸
縦軸に1軸のサンプルスコア、横軸に2軸のサンプルスコアをとり点グラフを作成します。
軸の名称はカテゴリスコアグラフと同じです。
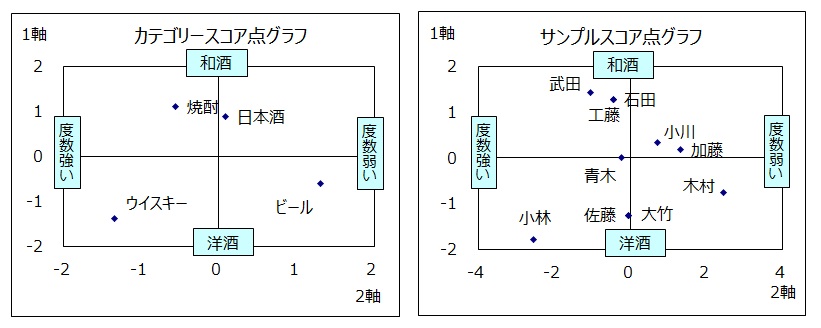
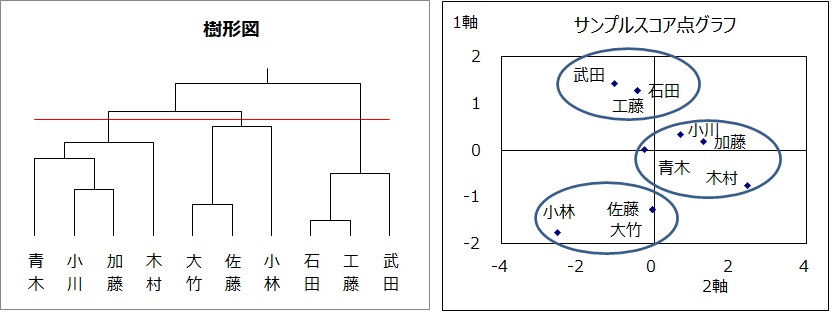
・和酒(焼酎と日本酒)が好きな石田と工藤は同じ位置
・洋酒(ウイスキーとビール)が好きな大竹と佐藤は同じ位置
・ウイスキーだけが好きな小林は左下に位置
・回答が全く異なる武田と小林は離れた位置
クラスター分析
クラスター分析は平面あるいは空間にプロットされた個体間の距離を調べ、距離の近い個体を集めて集落(クラスター)を作り、個体を分類する方法です。
個体間の距離の近さを樹形図で表します。
樹形図は個体間の距離を縦線の高さで表しています。
具体例のサンプルスコアのグラフを見ると、石田と工藤、大竹と佐藤は距離が
短いので樹形図の縦線の高さは低くなっています。小林はどの個体からも遠いので縦線の高さは最も高くなっています。
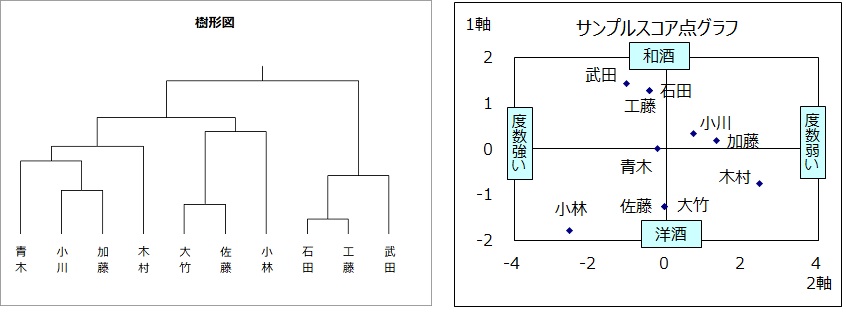
グループ数とグルーピング
グループの個数は分析者が設定します。
具体例のグループ数を3とします。
樹形図に横線を引きます。縦線との交点が定めたグループ数となるように引きます。
縦線と横線の交点から下に位置する個体を同じとします。
セグメント別人数
回答者は3個のセグメントに分類されました。
セグメント別人数、割合を計算します。
セグメントのネーミング
セグメントには名前を付けます。
ネーミングは、数量化3類に適用データとセグメントとのクロス集計の結果を用います。

セグメントとお酒とのクロス集計をしました。
お酒嗜好の割合から、セグメントの名前を付けます。
セグメント1
焼酎100%
↓
和酒派。
セグメント2
ウイスキー100%
↓
洋酒派
セグメント3
ビール100%
↓
ビール派
事例を用いて、多変量解析を適用して消費者をセグメンテーションし、関係をしらべてみましょう。
調査設計
①背景
生活態度、購買行動と新製品選択との関係を明らかにしたいことがあります。しかしながら人々の生活態度、購買行動は多種多様で、両者の因果関係の解明はやっかいなテーマといえます。そこで多変量解析を適用して消費者セグメントし、新製品選択との関係を調べることにします。
②目的
どのようなセグメントに属する人が、どのような新製品を嗜好するかを明らかにすることを目的とします。
③調査対象
20才以上59才以下の男女
④調査方法
インターネットWeb調査
⑤調査対象者の名簿
データベースを保有している会社の名簿
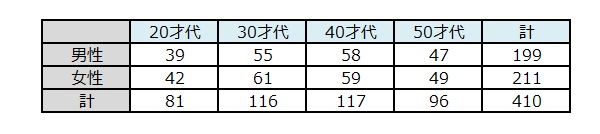
⑥サンプルサイズ
410人
※480人のデータを回収したが、不良な回答を除いて有効サンプルは410人となりました。
⑦標本抽出法
層別抽出法
データベースに登録している100万人を性別年代別の8グループに分類し、各グループに調査票を無作為に配信
⑧有効サンプルの内訳
調査票
消費者基本属性
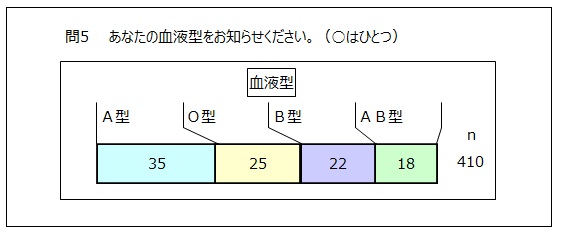
血液型の割合を調べると、割合の大きい順に、A型35%、O型25%、B型22%、AB型18%でした。
所得分布を調べると、399万円未満の割合は38%、400~799万円は37%、800万円以上は25%でした。年齢別の所得を調べると、年齢が高くなるほど所得が高くなる傾向が見られました。

生活態度
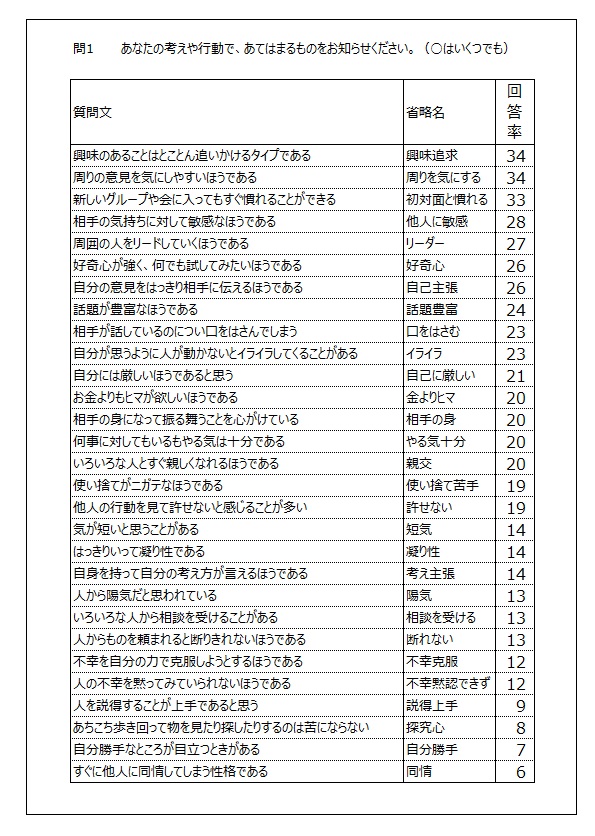
価値観、生活態度に関する29項目を示し、あなたの考えや行動に近いものはどれかを複数回答で聞きました。各項目の回答率を調べると、回答率が30%以上の項目数は3個、20%台は12個、10%台は10個、10%未満は4個でした。
ちなみに回答率が30%以上の項目は「興味追及」、「周りを気にする」、「初対面と慣れる」でした。
価値観、生活態度に関する29項目の類似点
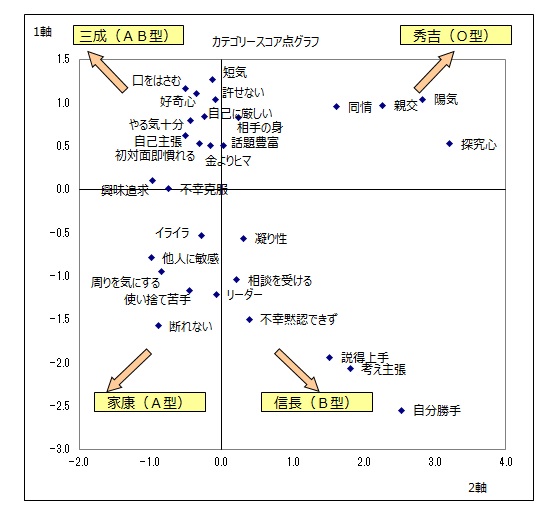
価値観、生活行動に関する29項目に数量化3類を適用しました。軸の重要度を示す相関係数が0.5以上の軸を採択しました。

1軸を縦軸、2軸を横軸にとり、カテゴリースコアの散布図を作成しました。
枠内の名称は後ほど掲載しております「グループの概要」の分析をもとにつけたものです。
人々のグルーピング
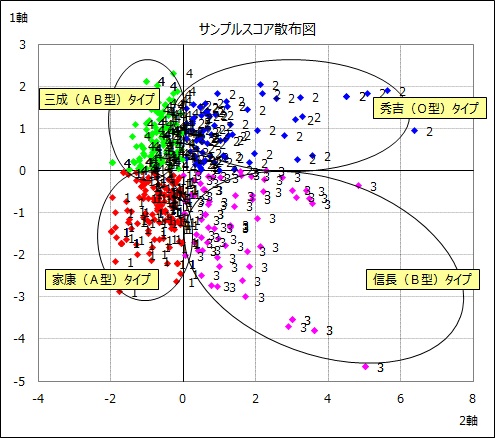
1軸を縦軸、2軸を横軸にとり、サンプルスコアの散布図を作成した。サンプルスコアのプロットが近い人を、クラスター分析によってグルーピングした。グループを生活態度タイプと呼ぶことにする。各タイプの配置は前ページのカテゴリースコアの配置と対応します。
グループの概要
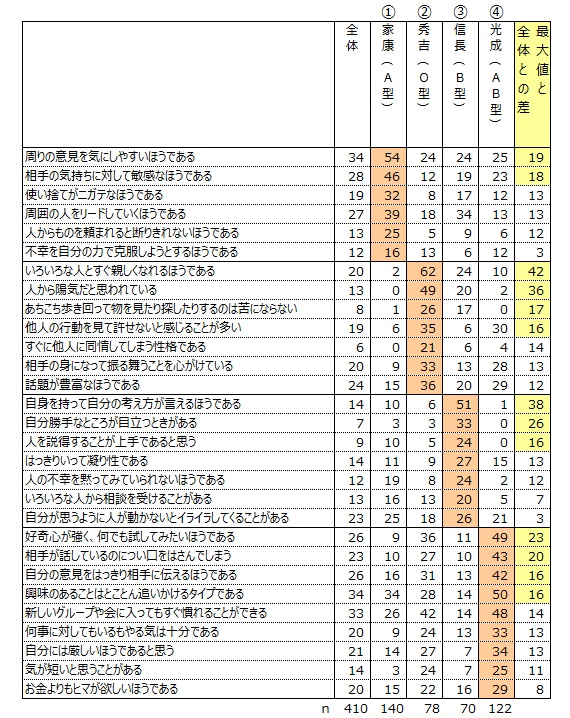
下記表の①~④の列の数値は、各グループにおける29項目の単純集計の回答率です。回答率を横に見て最大に彩色しました。最大値と全体との差を計算し、差が15ポイント以上の項目に着目しました。
家康(A型)タイプは、「周りの意見を気にしやすいほうである」、「相手の気持ちに対して敏感なほうである」の回答率が高い。
秀吉(O型)タイプは、「いろいろな人とすぐ親しくなれるほうである」、「人から陽気だと思われている」、「あちこち歩き回って物を見たり探したりするのは苦にならない」、「他人の行動を見て許せないと感じることが多い」の回答率が高い。
信長(B型)は、「自信を持って自分の考え方が言えるほうである」、「自分勝手なところが目立つときがある」、「人を説得することが上手であると思う」の回答率が高い。
三成(AB型)タイプは、「好奇心が強く、何でも試してみたいほうである」、「相手が話しているのについ口をはさんでしまう」、「自分の意見をはっきり相手に伝えるほうである」、「興味のあることはとことん追いかけるタイプである」の回答率が高い。
生活態度タイプの名称は、この解釈と次の分析より行いました。
属性別のグループ規模割合
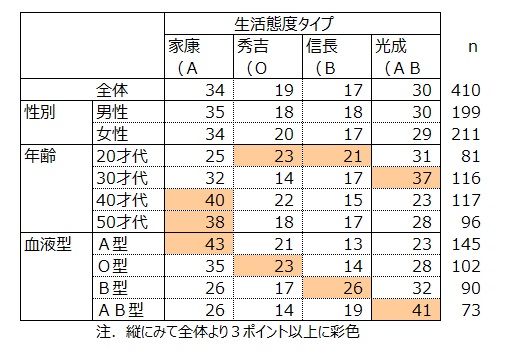
どのような属性の人でどのような生活態度タイプの割合が大きいかを調べました。
生活態度タイプの割合は男性と女性では差が見られませんでした。
年齢別では、20才代は「秀吉(O型)」と「信長(B型)」、30才代は「三成(AB型)」、40才代以上は「家康(A型)」が他年齢層を上回る割合を示しました。
血液型と生活態度タイプは、A型で家康、O型で秀吉、B型で信長、AB型で三成の割合が高くなる傾向がみられました。この傾向より、タイプ名の後尾に血液型を表記しました。
新製品意向
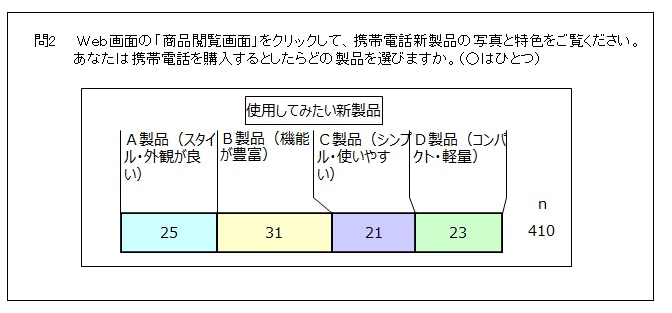
新製品の関心度、使用意向度
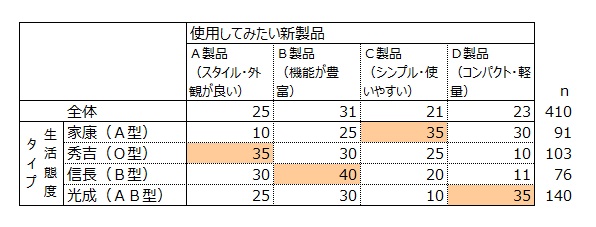
携帯電話新製品の使用意向を聞きました。B製品の使用意向が31%で最も高い割合を示しました。他3製品の使用意向は21~25%で大きな差は見られませんでした。
生活態度タイプの携帯電話新製品の使用意向度
生活態度タイプ別の携帯電話新製品の使用意向度を調べました。
家康(A型)タイプはC製品(シンプル・使いやすい)、秀吉(O型)タイプはA製品(スタイル・外観が良い)、信長(B型)タイプはB製品(機能が豊富)、三成(AB型)タイプはD製品(コンパクト・軽量)の意向率が他タイプに比べ高い値を示しました。