


《ロジスティック回帰(2/4) 》
カテゴリーデータと数量的データの関連性を調べる解析手法として相関比があります。 群はカテゴリーデータ、サンプルスコアは数量的データなのでこの例題に相関比を適用すると、相関比は0.674でした。
相関比の求め方を示します。
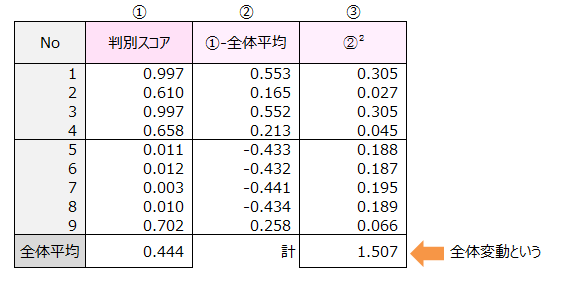
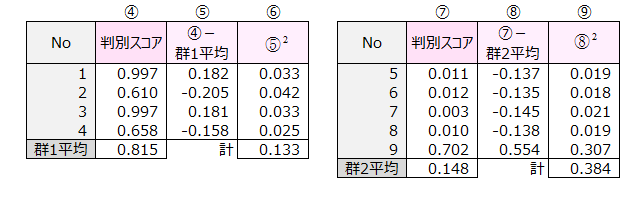
群内変動=⑥の計+⑨の計=0.133+0.384=0.517
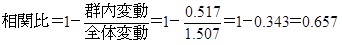
相関比は, 0~1 の値となります。 相関比は判別的中率同様に, いくつ以上あればよいという基準はありませんが, 筆者は0.5 を基準の値としています。 この例題の相関比は0.674 で0.5を上回ったので、関係は予測に適用できると判断します。
不健康有無の判別的中率は89%>75%、相関比は0.674>0.5より、関係式は予測に適用できると判断し、Wさんを予測します。
予測するWさんは 喫煙本数は25本、飲酒日数は15日です。
Wさんの予測値は

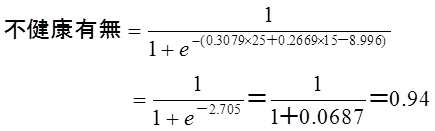
Wさんの不健康でる確率は94%です。
説明変数の選び方
ロジスティック回帰の説明変数は何でもよいということでありません。説明変数の選び方にはルールがあります。そのルールについて説明します。
①選択肢が3つ以上のカテゴリーデータの項目は適用できない。
説明変数に適用できるデータは数量データです。
飲酒日数、喫煙本数、性別、血液型から不整脈症状有無を予測したいと思います。
次の表のデータはロジスティック回帰に適用できるかを考えてみてくだい。
性別、血液型はカテゴリーデータなので、判別分析には適用できません。
ただし、カテゴリー数が2つの項目は適用できます。
・性別:男性→1 女性→0 として、数量データとして扱えます。女性→1 男性→0でもよいです。
・血液型:4カテゴリーなので適用できません。
②データがすべて同じ値の説明変数は、判別分析に適用できない。
アンケート調査で得た段階評価(1.よい 2.どちらともいえない 3.わるい)のデータを用いる場合などに、全員が「2・どちらともいえない」に回答する、といったことがたまにあります。この場合、この変数のデータはすべて「2」となり、この変数は判別分析に使えません。データがすべて同じだと標準偏差が0になるので、判別分析を行う前に標準偏差を計算してチェックして下さい。
③説明変数の個数は「個体数-1」より少なくなければならない。
説明変数の数をq、個体数をnとしたとき、ロジスティック回帰では次式を満足しなければなりません。
q<n-1
不健康有無のデータの場合、n-1は9-1=8です。q=2なので、q<n-1が成立し、判別分析が適用できました。この例においてはnが3以下だと判別分析は行えません。
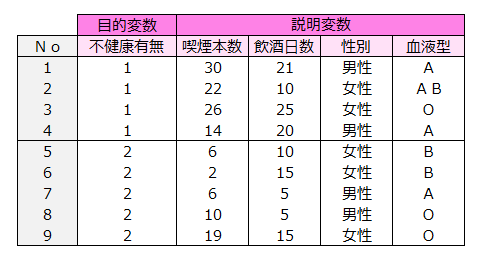
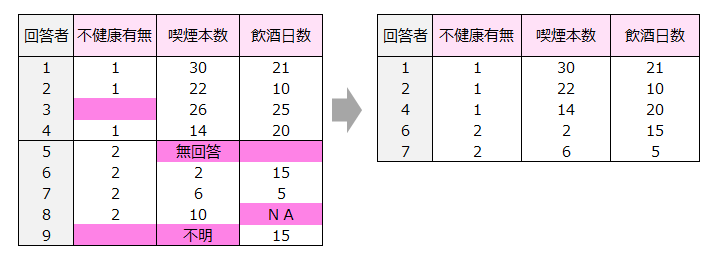
④数値以外のデータがある個体は分析から除外される。
ブランク、記号、文字などの数値以外のデータがある個体は分析から除外されます。
下記のデータの個体数は9人ですが、数値以外のデータがある個体数は4人存在するので、解析に適用できるデータは右表の5人となります。
ロジスティック回帰分析のオッズ比
ロジスティック回帰分析におけるオッズ比について説明します。
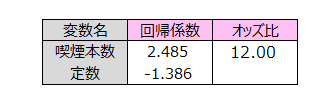
ロジスティック回帰のオッズ比は関係式の回帰係数から算出されます。
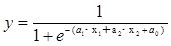
をオッズ比といいます。
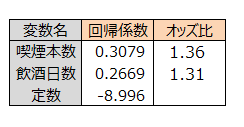

オッズ比は値が大きいほど、不整脈になるリスクが高いといえます。
しかし、オッズ比から倍率の解釈はできません。
喫煙本数が1日に1本増えると、不健康になる確率が1.36倍になるという解釈はできません。
オッズ比が1を下回ることがあります。例えば、説明変数にウォーキング有無があり、オッズ比が0.8だとします。「不健康」になるオッズ比は0.8ですので、逆数(1÷0.8=1.25)を計算し、ウォーキングの「健康」になるオッズ比は1.25という解釈もできます。
不健康有無の喫煙本数を1,0データに変換し、喫煙分類のデータを作成します。
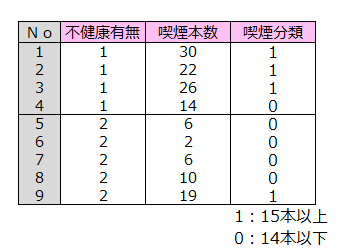
不整脈有無を目的変数、喫煙分類を説明変数とするロジスティック回帰を行います。
オッズ比は12.00でした。
このデータのリスク比とオッズ比を計算します。
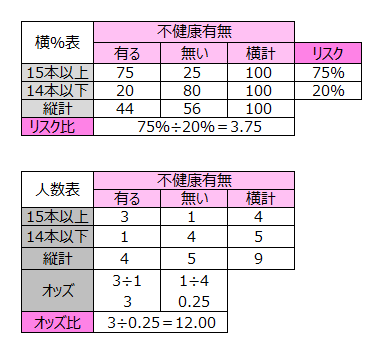
説明変数が1つの場合、ロジスティック回帰のオッズ比とクロス集計から算出されるオッズ比は一致します。
ロジスティック回帰の説明変数が2つ以上のオッズ比を「調整したオッズ比」、1つを単にオッズ比といいます。
統計的推定・検定の手法別解説
統計解析メニュー
最新セミナー情報

予測入門セミナー
予測のための基礎知識、予測の仕方、予測解析手法の活用法・結果の見方を学びます。

マーケティングプランニング&マーケティングリサーチ入門セミナー
マーケティングリサーチを学ぶ上で基礎・基本からの調査のステップ、機能までをわかりやすく解説しています。

統計解析入門セミナー
統計学、解析手法の役割から種類、概要までを学びます。

アンケート調査表作成・集計・解析入門セミナー
調査票の作成方法、アンケートデータの集計方法、集計結果の見方・活用方法を学びます。

